|
 |
|||
|---|---|---|---|
 |
|||
The present project is to develop the Arabic Learner Corpus. It currently comprises of 282,732 words, collected from learners of Arabic in Saudi Arabia. The corpus includes written and spoken data produced by 942 students, from 67 different nationalities studying at pre-university and university levels. The goal of the ALC is to provide an open-source of data for some linguistic research areas related to Arabic language learning and teaching. So, the corpus data is available for download in TXT and XML formats, hand-written sheets which are in PDF format as well as the audio recordings which are available in MP3 format. The Arabic Learner Corpus website
Three user-groups of specialists in Arabic Language Teaching are targeted by the Arabic Learner Corpus:
The ALC includes two general levels, the first level is named Pre-university, and it includes two parallel groups of learners, native Arabic speakers (NAS) learning at secondary schools and non-native Arabic speakers (NNAS) learning Arabic at institutions who teach Arabic as a second language. Both of these groups are counted as a pre-university, as it is the level they have to achieve before continuing their study at a university. The second level, University, is for both undergraduate and postgraduate learners of those specialising in the same target language, Arabic. Levels of the learners contributed to the ALC
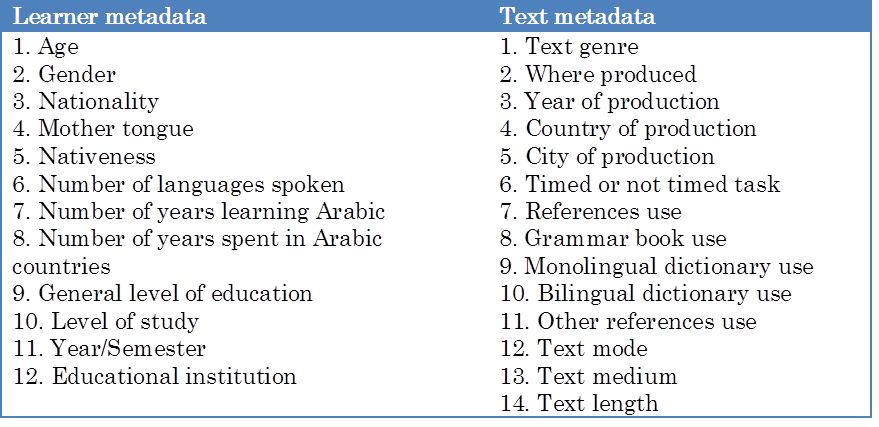
The corpus metadata includes 26 elements, 12 related to the learner and 14 associated with the text Metadata of the ALC
As the ALC is an open source project, the entire data of the corpus is available to download from the following website www.arabiclearnercorpus.com. It is available in different formats as shown in the table below. In addition, the user has the choice to download the whole corpus in one file (TXT or XML format), or to have each text in a separate file, 1585 files exist in the current version. File formats available on the ALC website
For more details please see the following paper about the corpus: Alfaifi, A., Atwell, E. and Hedaya, I. (2014). Arabic Learner Corpus (ALC) v2: A New Written and Spoken Corpus of Arabic Learners. In: Ishikawa, S (ed.) Learner corpus studies in Asia and the world. Vol. 2. Papers from LCSAW2014, pp. 77-89. Kobe, Japan: School of Languages and Communication, Kobe University. (link) |
|||
1st year of My PhD
|
|||
|
|||
Visit: |
|
Created 04-07-2012 |
Last updated 28-02-2015 |